2024. 9. 24. 11:11ㆍ금융공학/모델링
분산 투자의 핵심은 개별 자산의 변동성보다는 자산 간의 상관관계에 주목하여 포트폴리오 전체의 위험을 최소화하는 것입니다. 이는 현대 포트폴리오 이론(Modern Portfolio Theory, MPT)에서 중요한 개념으로, 자산 간의 상관관계가 낮을수록 포트폴리오의 전체 변동성을 줄일 수 있다고 설명합니다. 상관관계는 두 종목의 가격이 얼마나 비슷하게 움직이는지를 나타내는 지표입니다. 상관관계가 높다는 것은 두 종목의 가격이 비슷한 방향으로 움직이는 경향이 있다는 뜻이고, 상관관계가 낮다는 것은 서로 다른 방향으로 움직이는 경향 높다는 것을 의미합니다.

import numpy as np
import matplotlib.pyplot as plt
# 동적인 x 값 생성
x = np.linspace(0, 10, 100)
# 상관계수 = 1인 경우
y1_corr1 = np.sin(x)
y2_corr1 = np.sin(x) # 완벽한 양의 상관관계
# 상관계수 = 0인 경우
y1_corr0 = np.sin(x)
y2_corr0 = np.cos(x) # 상관관계 없음
# 상관계수 = -1인 경우
y1_corr_neg1 = np.sin(x)
y2_corr_neg1 = -np.sin(x) # 완벽한 음의 상관관계
# 2열 3행의 서브플롯 생성
fig, ax = plt.subplots(3, 2, figsize=(14, 12))
# 데이터를 리스트로 구성하여 반복문에서 사용
data = [
(y1_corr1, y2_corr1, "Correlation = 1"),
(y1_corr0, y2_corr0, "Correlation = 0"),
(y1_corr_neg1, y2_corr_neg1, "Correlation = -1"),
]
# 각 상관관계 시나리오에 대해 반복
for i, (y1, y2, title) in enumerate(data):
# 왼쪽 플롯: 시계열 데이터
ax[i, 0].plot(x, y1, label="y1")
ax[i, 0].plot(x, y2, label="y2")
ax[i, 0].set_title(f"{title} - Time Series")
ax[i, 0].legend()
# 분산과 공분산 계산
var_y1 = np.var(y1)
var_y2 = np.var(y2)
cov_y1_y2 = np.cov(y1, y2)[0, 1]
# 자산 가중치 설정
w = np.linspace(0, 1, 100)
# 포트폴리오 분산 공식
var_p = (
w**2 * var_y1
+ (1 - w) ** 2 * var_y2
+ 2 * w * (1 - w) * cov_y1_y2
)
# 오른쪽 플롯: 분산투자 효과
ax[i, 1].plot(w, var_p, label="Portfolio Variance")
ax[i, 1].set_title(f"{title} - Diversification Effect")
ax[i, 1].set_xlabel("Weight of y1")
ax[i, 1].set_ylabel("Portfolio Variance")
ax[i, 1].legend()
ax[i, 1].grid(True)
plt.tight_layout()
plt.show()
장단점:
포트폴리오를 구성할 때 상관관계가 낮은 종목들과 높은 종목들을 선택하는 것은 각각 다른 장단점을 가지고 있습니다. 상관관계가 낮은 종목들로 포트폴리오를 구성하면, 특정 종목이 하락할 때 다른 종목이 상승하거나 덜 하락하게 되어 전체 포트폴리오의 변동성이 줄어들고 안정성이 높아집니다. 이는 투자자가 심리적으로 더 안정을 느끼게 하고, 예상치 못한 손실을 줄이는 데 도움이 됩니다. 또한, 다양한 시장 상황에서도 포트폴리오의 성과를 일정하게 유지할 수 있어 장기 투자에 유리합니다.
단, 상관관계가 낮은 종목들로 포트폴리오를 구성할 때 종목들이 서로 다른 방향으로 움직이기 때문에, 한 종목이 상승할 때 다른 종목이 하락하거나 그만큼 오르지 않는 경우가 많아 전체 포트폴리오의 수익률이 낮아질 수 있습니다. 또한, 상관관계가 낮은 종목을 선택하다 보면, 서로 다른 산업군이나 지역에 걸쳐 분산 투자하게 되어, 시장의 특정 테마나 강세장을 충분히 활용하지 못할 가능성도 있습니다. 이는 단기적으로 높은 수익을 추구하는 투자자에게는 매력적이지 않을 수 있으며, 지나치게 분산된 포트폴리오는 관리가 복잡해지는 단점도 있습니다.
관련 용어:
- 분산 투자(Diversification): 서로 다른 자산군 또는 종목들로 포트폴리오를 구성하여 위험을 줄이는 투자 전략.
- 비상관 자산(Non-Correlated Assets): 상관관계가 거의 없거나 낮은 자산들로, 서로 다른 움직임을 보이는 자산.
- 포트폴리오 최적화(Portfolio Optimization): 위험 대비 수익률을 최적화하는 포트폴리오를 구성하는 과정.
- 리스크 분산(Risk Diversification): 상관관계가 낮은 자산을 사용하여 전체 포트폴리오의 리스크를 줄이는 전략.
상관 관계가 낮은 종목 찾고 구성하기:
먼저 데이터를 가져옵니다. 티커들은 임의의 ETF 여러 개로 구성했습니다.
import yfinance as yf
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import itertools
tickers = [
'SCHD', 'SPY', 'QQQ', 'VIG', 'BND', 'IVV', 'VOO', 'VTI', 'DIA', 'IWM',
'EFA', 'XLK', 'XLF', 'XLE', 'XLV', 'XLY', 'XLI', 'XLP', 'XLB', 'VNQ',
'VYM', 'TLT', 'IEF', 'TIP', 'AGG', 'LQD', 'HYG', 'JNK', 'SHY', 'MUB', 'SPDW'
]
data = yf.Tickers(tickers)
history = data.history(period='max')
history['Dividends'] = history['Dividends'].fillna(0)
history = history.dropna()
div_data_daily = history.Dividends
price_data_daily = history.Close
price_data_annual = price_data_daily.resample('YE').mean()
div_data_resampled = div_data_daily.resample('YE').sum()
아래의 코드는 주어진 주식 가격 데이터에서 상관관계가 가장 낮은 종목 조합을 찾는 함수로, 포트폴리오 구성을 도와줍니다.
def find_lowest_corr_pairs(price_data, N=2, fixed_ticker=None):
# 가격 데이터의 상관관계 행렬 계산
correlation_matrix = price_data.corr()
# 사용 가능한 티커 목록 추출
tickers = correlation_matrix.columns
all_results = [] # 모든 결과 저장 리스트
# N을 2부터 주어진 N까지 반복
for current_N in range(2, N+1):
print(f"Searching for combinations with N={current_N}...")
# 고정된 티커가 있는 경우 처리
if fixed_ticker:
# 고정된 티커가 데이터에 없으면 오류 발생
if fixed_ticker not in tickers:
raise ValueError(f"Fixed ticker {fixed_ticker} is not in the price data.")
# 고정된 티커를 제외한 N-1개의 티커 선택
other_tickers = [ticker for ticker in tickers if ticker != fixed_ticker]
ticker_combinations = [(fixed_ticker,) + comb for comb in itertools.combinations(other_tickers, current_N-1)]
else:
# 고정된 티커가 없으면 N개의 티커 조합 생성
ticker_combinations = list(itertools.combinations(tickers, current_N))
# 각 조합에 대해 평균 상관관계 계산
for comb in ticker_combinations:
# 해당 티커 조합의 상관관계 행렬 추출
sub_corr_matrix = correlation_matrix.loc[comb, comb]
# 자기 자신과의 상관관계를 제외한 평균 상관관계 계산
avg_corr = sub_corr_matrix.where(~np.eye(current_N, dtype=bool)).mean().mean()
all_results.append((comb, avg_corr))
# 평균 상관관계가 낮은 순으로 정렬
sorted_corr_pairs = sorted(all_results, key=lambda x: x[1])
# 상관관계가 낮은 30개의 조합을 출력
top_results = sorted_corr_pairs[:30]
print("\nThelowest correlation combinations:")
for comb, avg_corr in top_results:
print(f"Combination: {comb}, Average Correlation: {avg_corr}")
return top_results
# 예시 실행
lowest_corr_tickers = find_lowest_corr_pairs(price_data_daily, N=3, fixed_ticker=None)
이 함수는 포트폴리오 구성 시 상관관계가 낮은 주식 조합을 찾는 데 유용합니다. N은 조합할 최대 종목 수를 지정하며, 예를 들어 N=4로 설정하면 2개부터 4개까지의 종목 조합 중에서 상관관계가 가장 낮은 조합을 찾습니다.
fixed_ticker는 특정 종목을 반드시 포함하도록 설정할 수 있으며, 기본값은 None입니다. 예를 들어, 'SPY'를 입력하면 'SPY'를 반드시 포함한 조합을 찾습니다. 이를 통해 특정 종목을 중심으로 상관관계가 낮은 다른 종목들과의 조합을 만들 수 있습니다.
마지막으로 이 결과를 도식화하는 코드를 추가합니다. 분산 투자 포트폴리오 스터디와 구성에 도움이 되기를 바랍니다.
def plot_lowest_corr_pairs(lowest_corr_tickers):
# 티커 조합과 평균 상관관계를 분리
combinations = [', '.join(comb) for comb, _ in lowest_corr_tickers]
avg_correlations = [avg_corr for _, avg_corr in lowest_corr_tickers]
# 막대 그래프 그리기
plt.figure(figsize=(10, 6))
plt.barh(combinations, avg_correlations, color='skyblue')
plt.xlabel('Average Correlation')
plt.ylabel('Ticker Combinations')
plt.title('Top 30 Lowest Correlation Ticker Combinations')
plt.gca().invert_yaxis()
plt.grid(True, axis='x', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
plot_lowest_corr_pairs(lowest_corr_tickers)
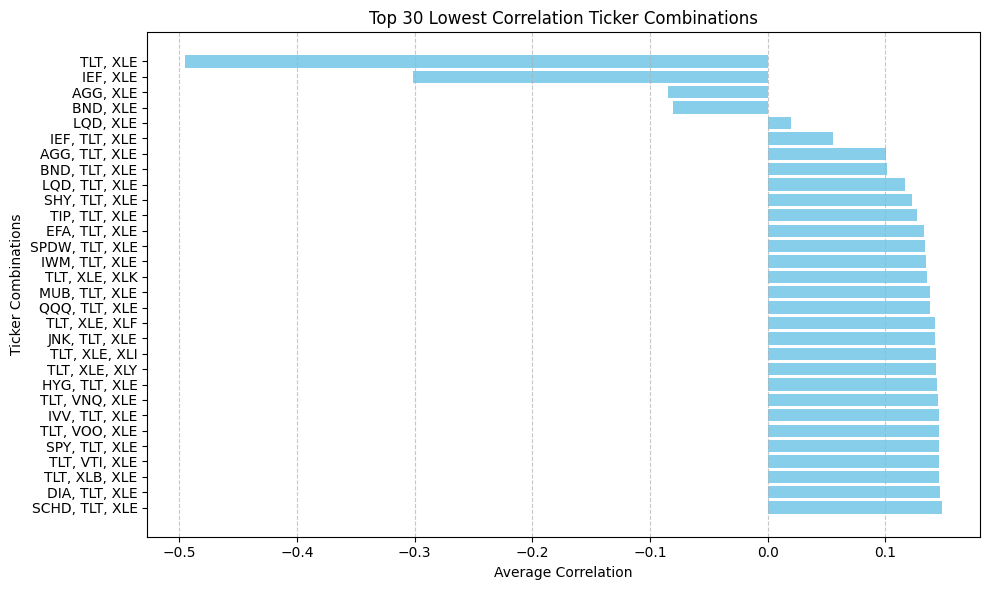
다음 포스트에서 이렇게 조합된 포트폴리오의 투자 가치와 장단점에 대해 살펴보겠습니다.
'금융공학 > 모델링' 카테고리의 다른 글
| [Quant] 팩터와 알파 (0) | 2024.11.13 |
|---|---|
| CAPM, Fama-French 다중 팩터 모델과 오늘날 퀀트 (5) | 2024.11.12 |
| [Quant] 퀀트 투자 용어 (1) (3) | 2024.10.22 |
| [MPT] 적립식 배당성장주 투자의 가치 및 포트폴리오 최적화 (7) | 2024.09.22 |